
💰Big Tech’s $700B Capex Spree and Anthropic’s $900B Valuation Question
Pus: What Are AI Evals and Why Do They Matter?

The Anthropic valuation is raising a lot of skepticism, but it seems that when looking at the numbers and their revenue rate, it may make sense after all. We shall see. But anthropic is not the only one bringing in big numbers, the Capex spree of $700 is extremely large and still not satisfying demand. Where do we go from here? Let's discuss. Also, how to install your local LLM model for sensitive research and data, and which one to choose? We share a few. Stay Curious
Big Tech’s $700B Capex Spree and Anthropic’s $900B Valuation Question
Alphabet’s Q1 2026: The AI Bet Pays Off
The $700 Billion Capex Arms Race
Breakdown of Big Tech 2026 Capex Guidance
Anthropic’s $900 Billion Valuation: Justifiable or Froth?
🧰 AI Tools - Best Open Source models for Local LLMs
What Are AI Evals and Why Do They Matter?
📚Learning Corner - How to Run LLMs locally. A step-by-step guide.
📰 AI News and Trends
OpenAI has abandoned much of its Stargate plan, and it will no longer develop its own data centers
Citi is rolling out a new internal AI platform that lets employees create agents, tapping into top models within one secure system that can scale those agents across the firm.
Nvidia’s Banned B300 Servers Hit $1 Million in China’s Black Market. US export controls and a crackdown on chip smuggling have driven the price to twice as much. Chinese tech firms are scrambling for the hardware despite the risk of US sanctions exposure, with some turning to rentals as high as 190,000 yuan per month as grey-market supply dries up.
Samsung's Chip Profits Explode 49-Fold as AI Memory Crunch Deepens. Samsung Electronics posted a record Q1 2026 operating profit of 57.2 trillion won (~$38.5B), with its chip division alone surging from 1.1 trillion to 53.7 trillion won in a single year, a nearly 49-fold leap.
Big Tech's AI Spending Spree Tops $700 Billion and Counting. Alphabet, Amazon, Microsoft, and Meta collectively plan to spend as much as $725 billion on capital expenditures in 2026, almost entirely to build out AI data center infrastructure.
Google's AI Bet Pays Off in a Big Way Cloud Revenue Surges 63% Alphabet blew past Wall Street expectations in Q1 2026, reporting $109.9B in total revenue (up 22% YoY) with Google Cloud alone hitting $20B, a staggering 63% jump driven by AI demand.
Other Tech News
Musk was fine with a for-profit OpenAI when he thought he could control it, but turned against it when he realized he wasn’t able to control it, and now acts as the AI saviour. But his products post racist messages, create nonconsensual images of adults, and generate explicit images of children.
Meta told it’s violating EU law by not doing enough to keep children off Facebook and Instagram.
Anthropic, OpenAI Splurge on London Offices in Leasing Wave, while Startup Offices in NYC Are Flashy but Mostly Empty
Emergency First Responders Say Waymos Are Getting Worse
Big Tech’s $700B Capex Spree and Anthropic’s $900B Valuation Question

I am becoming a bit skeptical of the Anthropic’s valuations. Can they justify raising yet another $100B to reach almost the $1 Trillion valuation? How can they keep up with costs? Are their clients as loyal as they may think? I do understand that the artificial intelligence landscape in early 2026 is defined by staggering numbers. As Big Tech companies report their first-quarter earnings, the narrative is clear: the AI boom is generating massive revenue, but it requires an unprecedented scale of capital expenditure to sustain. At the center of this frenzy are the hyperscalers, Alphabet, Amazon, Microsoft, and Meta, and the frontier model builders like OpenAI and Anthropic.
Alphabet’s blowout Q1 earnings were driven by Google Cloud, the collective $700 billion capital expenditure (capex) plans of Big Tech, and Anthropic’s reported pursuit of a $900 billion valuation.
Alphabet’s Q1 2026: The AI Bet Pays Off
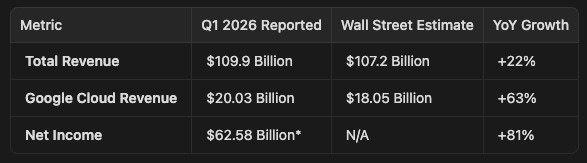
Alphabet’s first-quarter 2026 earnings report served as a powerful vindication of its massive investments in AI. The company reported total revenue of $109.9 billion, a 22% year-over-year increase that comfortably beat Wall Street’s $107.2 billion estimate.
The undisputed star of the quarter was Google Cloud. The division reported $20.03 billion in revenue, representing a staggering 63% year-over-year growth. This performance significantly outpaced analysts’ expectations of $18.05 billion and marked a sharp acceleration from the 48% growth seen in the previous quarter.
Alphabet CEO Sundar Pichai highlighted that enterprise AI solutions have become the primary growth driver for Google Cloud for the first time. The company’s full-stack approach to AI is yielding results across the board, with Search queries hitting an all-time high and the Gemini Enterprise platform seeing a 40% quarter-over-quarter increase in paid monthly active users.
Despite the massive revenue surge, Google remains compute-constrained. “Our cloud revenue would have been higher if we were able to meet the demand,” Pichai noted during the earnings call. This constraint underscores the necessity of the massive infrastructure build-out currently underway across the industry.
The $700 Billion Capex Arms Race
The demand for AI compute has triggered what analysts are calling the largest concentrated infrastructure cycle in tech history. The four major hyperscalers, Alphabet, Amazon, Meta, and Microsoft, are collectively projected to spend between $650 billion and $725 billion on capital expenditures in 2026.
This spending is almost entirely directed toward building out AI data center infrastructure, including land, power, buildings, servers, and highly sought-after AI accelerators (GPUs and TPUs).
Breakdown of Big Tech 2026 Capex Guidance
Amazon: ~$200 Billion
Microsoft: ~$190 Billion (Up 61% from 2025)
Alphabet: $180 Billion – $190 Billion
Meta: $125 Billion – $145 Billion
The sheer scale of this investment is causing some unease among investors, with concerns about free cash flow and the potential for a “capital misallocation” if AI revenue doesn’t keep pace with infrastructure costs. For instance, Amazon reported that its free cash flow decreased to $1.2 billion for the trailing 12 months, a 95% drop year-over-year, driven primarily by a $59.3 billion increase in property and equipment purchases.
However, tech executives remain resolute. Amazon CEO Andy Jassy compared the current environment to the early days of AWS, noting that “the faster AWS grows, the more short-term capex we’ll spend”. Microsoft CFO Amy Hood attributed part of their $190 billion capex forecast to a $25 billion impact from higher component prices, specifically citing soaring memory costs driven by the global AI hardware crunch.
Anthropic’s $900 Billion Valuation: Justifiable or Froth?
Against the backdrop of Big Tech’s infrastructure spending, frontier AI lab Anthropic is reportedly in talks to raise fresh capital at a valuation of more than $900 billion. If successful, this would push Anthropic past its chief rival, OpenAI, which was valued at $852 billion in March 2026.
Anthropic’s valuation has skyrocketed over the past year. In February 2026, the company raised $30 billion at a $380 billion valuation. A jump to $900 billion in just a few months raises the critical question: Can the company justify this price tag?
The Bull Case for $900 Billion
The justification for Anthropic’s soaring valuation rests on its explosive revenue growth, its deepening entrenchment in the enterprise sector, and the breakout success of its latest models.
Hyper-Growth Revenue: Anthropic recently announced that its annualized revenue run rate has surpassed $30 billion, a dramatic increase from approximately $9 billion at the end of 2025. Some sources suggest the current run rate is closer to $40 billion.
Enterprise Dominance: Unlike OpenAI, which has a massive consumer footprint with ChatGPT, Anthropic has focused heavily on B2B applications. Over 55% of Anthropic’s revenue comes from enterprise and API usage. The company reported that the number of business customers spending over $1 million annually doubled from 500 to over 1,000 in less than two months.
The “Mythos” Factor: In early April, Anthropic unveiled a new model called Mythos, purportedly able to detect and exploit vulnerabilities in critical software. Deemed too dangerous for wide release, it is currently being tested by a limited group of companies. The model has sparked global alarm, high-profile meetings with the Trump administration, and even testing by the NSA. The massive compute required to run Mythos is a key driver behind Anthropic’s current fundraising push.
Strategic Backing: Anthropic has secured massive financial and infrastructure commitments from Big Tech. Google recently committed to invest $10 billion at a $350 billion valuation, with plans to invest up to another $30 billion if performance targets are met. Amazon is also investing $5 billion at the same $350 billion valuation, with plans to inject $20 billion more over time. Furthermore, Anthropic has secured multiple gigawatts of next-generation compute capacity through partnerships with Google, Broadcom, and Amazon.
The Valuation Math and IPO Horizon
If Anthropic is generating a $30 B to $40 B annualized revenue run rate, a $900 billion valuation implies a revenue multiple of roughly 22x to 30x. While high by traditional software standards, this multiple is actually a compression compared to earlier stages of the AI boom. The rapid growth in actual revenue is helping the company “grow into” its massive valuation.
This fundraising push comes at a critical time. Anthropic is reportedly considering an initial public offering (IPO) as soon as October 2026. As Anthropic gains momentum, it is putting immense pressure on OpenAI, which is also expected to go public soon but has reportedly missed some revenue and user growth targets amid the fierce competition.
The intersection of Alphabet’s 63% cloud growth, Big Tech’s $700 billion capex commitments, and Anthropic’s push for a $900 billion valuation paints a picture of an industry in the midst of a historic platform shift.
The hyperscalers are spending unprecedented sums because the enterprise demand for AI, evidenced by Google Cloud’s numbers and Anthropic’s $30B+ run rate, is materializing faster than expected. Anthropic’s potential $900 billion valuation, while staggering, is anchored by real, hyper-scaling enterprise revenue, the breakout success of models like Mythos, and massive compute resources secured through its Big Tech partnerships. Securing the capital and infrastructure to deploy AI at a global scale is the real AI war today.
📚Learning Corner
What Are AI Evals and Why Do They Matter?
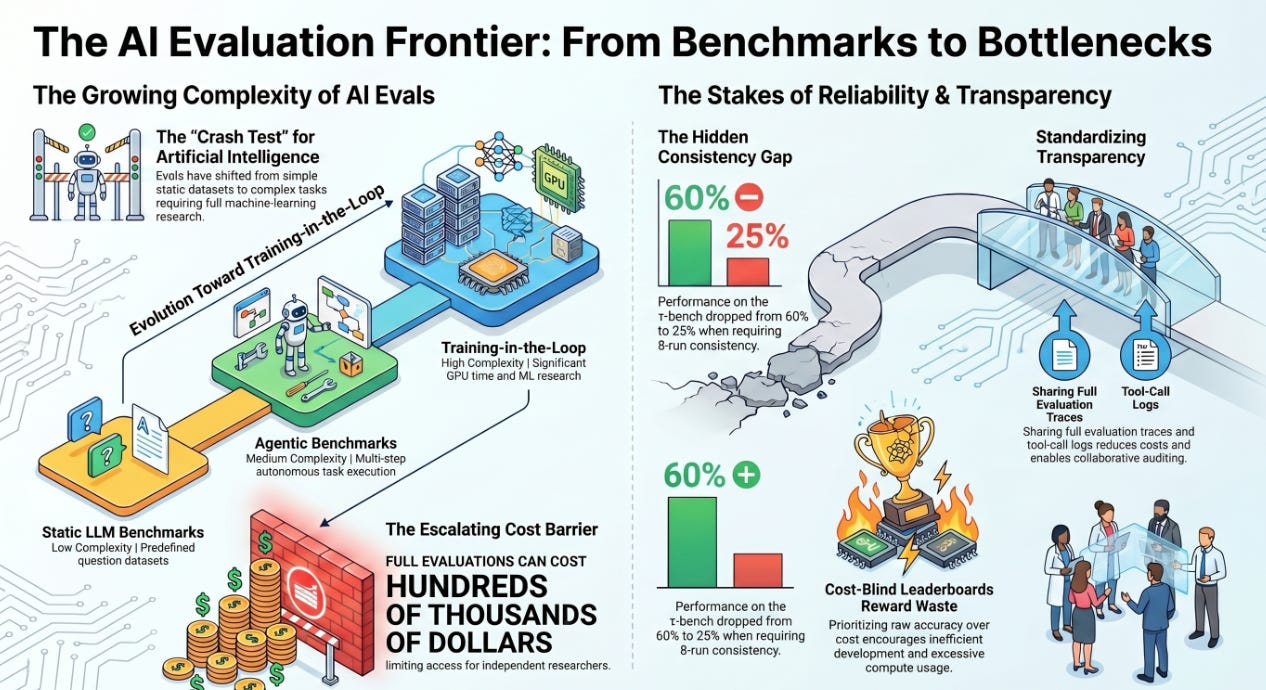
Artificial Intelligence evaluation (evals) is the critical process of testing and measuring the capabilities, reliability, and safety of AI models and agents. Similar to crash tests for vehicles or clinical trials for pharmaceuticals, evals provide standardized benchmarks to assess AI performance before and during deployment.
According to the article “AI evals are becoming the new compute bottleneck” by Avijit Ghosh et al., AI evaluation has transformed from a relatively inexpensive process into a significant computational and financial challenge impacting the entire AI ecosystem.
Types of AI Evals
AI evals have evolved to match the increasing complexity of AI systems:
Static LLM Benchmarks: Initially, evals for Large Language Models (LLMs) involved static datasets, where models were graded on predefined questions. These were efficient, with methods like Flash-HELM allowing for 100× to 200× compression while maintaining accurate model ranking.
Agentic Benchmarks: With the rise of autonomous AI agents capable of multi-step tasks (e.g., web navigation, coding), evals became more complex. Agentic benchmarks like GAIA and SWE-bench are costly and intricate, as a single task involves numerous steps, and failure at any point can invalidate the entire run.
Training-in-the-Loop Benchmarks: The most advanced evals now require AI to perform actual machine learning research or train new models. Benchmarks such as The Well (for scientific ML) and PaperBench (for replicating research) demand significant GPU resources and time, essentially making the evaluation a full training process.
Why Evals Are Crucial for Everyone
Despite their technical nature, AI evals have broad implications for society, governance, and the future of AI:
Defining “Good” AI: Evals establish the standards for AI progress. However, leaderboards that prioritize raw accuracy over cost and reliability can be misleading, fostering inefficient development. “Cost-blind leaderboards reward waste,” encouraging excessive compute usage without necessarily improving efficiency or reliability.
Revealing Unreliability: Modern evals highlight that AI agents often lack reliability. A model might perform well once but fail inconsistently on repeated attempts. For instance, performance on the τ-bench dropped from 60% to 25% when requiring 8-run consistency. Rigorous, repeated testing is vital to prevent deploying seemingly capable but unpredictably failing AI systems.
Creating an Accountability Barrier: The cost of comprehensive evaluations has escalated dramatically, with single runs costing thousands and full evaluations potentially hundreds of thousands of dollars. This financial burden creates a barrier for academic institutions, AI Safety Institutes, and independent journalists, limiting their ability to independently verify claims made by frontier AI labs. As the article states, “Whoever can pay for the evaluation gets to write the leaderboard”.
Shaping AI Safety and Governance: Evals are fundamental for AI regulation, measuring safety and risk. Governance bodies need to understand the disparity between a model’s single-run accuracy and its consistent reliability. The high cost of measuring this gap hinders regulators’ capacity to audit powerful AI systems effectively.
The Way Forward
The escalating cost of evals necessitates a collaborative solution. Standardized documentation and data sharing are the most effective ways to reduce costs and enhance transparency. By publishing full evaluation traces, including prompts, scaffolds, and tool-call logs, researchers can build upon existing data, avoiding redundant testing. Initiatives like the EvalEval Coalition’s “Every Eval Ever” project aim to create a shared format for this data, promoting reuse and analysis within the community.
In essence, AI evals are no longer a minor technical detail; they are the foundational infrastructure for measuring, trusting, and governing artificial intelligence. Ensuring their rigor, transparency, and accessibility is paramount for the safe and equitable advancement of AI.
🧰 AI Tools of The Day
Best Open Source models for Local LLMs - As discussed yesterday with Dr. Sam Illinworth, getting an open source local LLM model for your personal research and queries is the best option. Here are 3 to consider:
Qwen 3.5 (The Best All-Rounder) - The gold standard for local users. It consistently beats proprietary models like GPT-5-mini in benchmarks and offers incredible performance in coding and multilingual tasks.
Best For: General purpose, high-end coding, and 200+ languages.
Llama 4 Scout (The Context King - 109B total / 17B active parameters) - The first choice for users who need to process massive amounts of data locally.
Best For: Document analysis, long-form writing, and RAG (Retrieval-Augmented Generation).
DeepSeek-R1 (The Reasoning Powerhouse) - If your goal is complex problem-solving, math, or deep logic, DeepSeek-R1 remains the top choice. It uses a “Chain-of-Thought” (CoT) reasoning process similar to OpenAI’s o1 series.